

ИИ для работы с документами: как мы заменили ручной перенос данных на ИИ-конвейер
- Заказчик
- Российская строительная компания из Москвы, работающая на рынке промышленного и гражданского строительства РФ
- Задача
- создать корпоративный ИИ для бизнеса, адаптированный под российский рынок и мультиязычную документацию, который сам распознаёт сканы, понимает содержимое и выдаёт готовый Excel в нужном формате
Задача
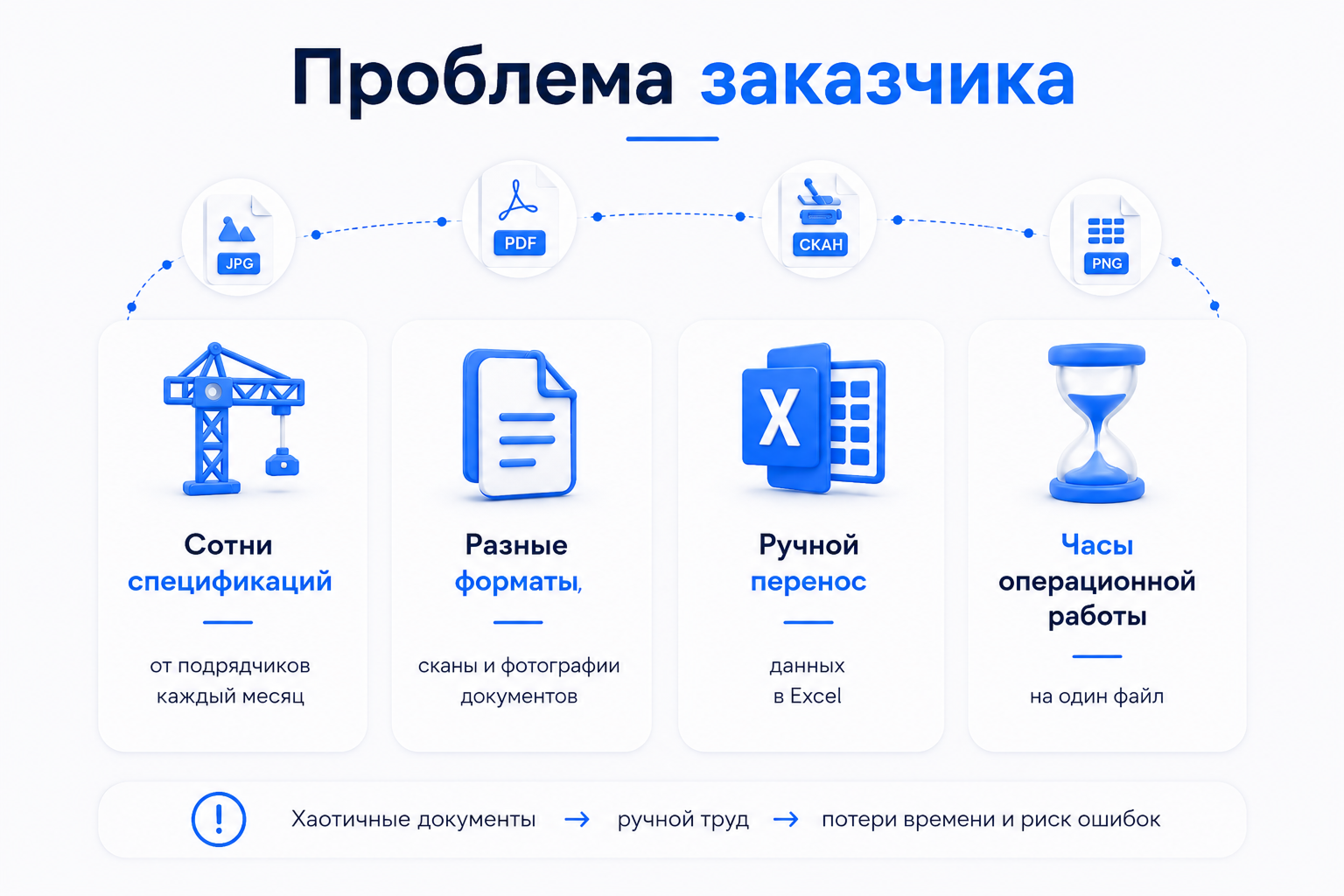
Заказчик — российская строительная компания из Москвы, работающая на рынке промышленного и гражданского строительства РФ. Операционный блок ежемесячно обрабатывает сотни смет и спецификаций от десятков подрядчиков со всей страны и из-за рубежа. Документы приходят на русском и английском языках в хаотичных форматах: разные названия колонок, нестандартная структура таблиц, небрежные сканы и фотографии вместо нормальных PDF.
Проблема: сотрудники часами вручную переписывали каждую позицию в корпоративную таблицу. Монотонная работа, выматывающая и чреватая ошибками. Анализ системы управления документами показал: до 70% времени уходит на механический перенос данных.
Цель: создать корпоративный ИИ для бизнеса, адаптированный под российский рынок и мультиязычную документацию, который сам распознаёт сканы, понимает содержимое и выдаёт готовый Excel в нужном формате. Исключить ручной перенос данных.
С чего мы начали: мы решили строить не готовый продукт сразу, а прототип — проверить ключевую механику распознавания и сопоставления, показать заказчику работающий конвейер и собрать обратную связь. Никаких жёстких требований к дизайну, удобству интерфейса и масштабируемости на этом этапе не было — только точность распознавания и корректность выгрузки. Поскольку глубокая фронтенд-проработка не требовалась, интерфейс строили с помощью генерации кода. Это позволило реализовать весь проект силами одного разработчика.
Стек: Python, FastAPI, OpenCV, EasyOCR, LangChain, YandexGPT, GigaChat, Flutter.
Решение
С чем мы столкнулись
На старте мы провели аудит входящей документации и выявили нюанс, который не был очевиден. Предполагалось, что входные данные — PDF с текстовым слоем: извлекаешь и раскладываешь. По факту заказчик использовал «мёртвые» сканы, просто картинки без возможности копирования. Текст — набор цветных точек. Нужно не «прочитать», а «увидеть» и «понять». Это меняло архитектуру: требовалось не извлечение текста, а полноценное компьютерное зрение.
Мы не просто взялись строить своё — мы проверили существующие решения. Протестировали платный аналог за 20 $/мес. Таблицы он отрисовывал неплохо, но ошибался в цифрах и названиях. Для российского бизнеса, где одна ошибка грозит срывом сроков и финансовыми потерями, это не годилось. Нужна была автоматизация проверки документов, встроенная прямо в процесс.

Как мы построили ИИ-конвейер
Мы спроектировали поэтапный конвейер из четырёх шагов.
Шаг 1. Извлечение сырых данных. Пользователь загружает изображение и выделяет область с таблицей — на листе могут быть печати, заметки, подписи. Компьютерное зрение нормализует картинку, находит строки и столбцы, извлекает текст. Мы осознанно перебрали несколько OCR-библиотек и выбрали оптимальную по точности для русского и английского языков.
Шаг 2. Интеллектуальное сопоставление. Нейросеть получает две сущности: колонки из входящего документа и колонки целевой таблицы заказчика. Задача — найти смысловые соответствия. Примеры: «Масса единицы» у поставщика → «Вес изделия» у заказчика. Сложнее: «Труба ДН677 600» — это не одна колонка, а две: «Труба» ? наименование, «ДН677 600» ? техническая характеристика. Нейросеть сама разделяет такие данные и распределяет по нужным полям, в том числе в международных документах, где терминология может отличаться. Оркестрация — через LangChain, модели — ЯндексGPT и GigaChat.
Шаг 3. Верификация. Мы не обещаем 100% точности — это технологически невозможно, и ни один зрелый сервис таких гарантий не даёт. Вместо этого мы встроили в архитектуру промежуточный экран, где пользователь видит распознанное, сверяет с исходной картинкой и за секунды правит ошибки. Автоматизация проверки документов — не заплатка, а часть архитектуры, которая обеспечивает гарантированно корректный финальный результат.
Шаг 4. Выгрузка. Пользователь нажимает «подтвердить» и скачивает готовый Excel в едином корпоративном формате.

Генерация кода как инженерный инструмент
Поскольку на этапе прототипа не требовалась глубокая фронтенд-проработка, мы использовали генерацию кода для создания интерфейса на Flutter. Разработчик описывал желаемый UI, ИИ генерировал код, который затем проходил ревью и дорабатывался. Это позволило реализовать весь проект силами одного специалиста и кратно сократить время: интерфейс, достаточный для демонстрации заказчику и сбора обратной связи, был собран за часы.
При этом мы отдаём себе отчёт в ограничениях: ИИ дописывает новый код поверх старого, не удаляя неиспользуемое, кодовая база быстро распухает. Без профильной экспертизы разработчик не может оценить качество и заметить неоптимальности. Поэтому для перехода от прототипа к стабильному продукту сгенерированный код требует профессионального ревью — это наше принципиальное требование к качеству.
Результат
? Документ, на который раньше уходил час ручного труда, теперь обрабатывается за несколько минут. Время сократилось в 5–7 раз.
? Московский заказчик, годами делавший это руками, был готов к 30% точности. Фактическая точность оказалась значительно выше ожиданий.
? Сотрудники перестали бояться входящих спецификаций: загрузил фото ? проверил ? поправил за пару кликов ? выгрузил.
? Прототип подтвердил ключевую механику: конвейер корректно распознаёт и сопоставляет данные даже в международных документах на русском и английском языках.
? Генерация кода кратно ускорила прототипирование, но для промышленного продукта требует профессионального ревью — это учтено в дальнейших планах.
? Конвейер не привязан к стройке. Та же задача есть в логистике, гостиничном бизнесе, финансах. Масштабирование корпоративного ИИ для бизнеса на другие индустрии и международные рынки — вопрос адаптации нейросетевого слоя под новую доменную модель.

