

Развитие и техническая поддержка сервиса для заказчиков и поставщиков
- Заказчик
- СТАР - Система Торговых Аналитических Решений, платформа, которая помогает покупателям и заказчикам найти закупки и заключать сделки онлайн
- Задача
- Развитие и техническая поддержка сервиса, обновление системы поиска и мофрологического подбора закупок
Система торговых аналитических решений (СТАР) – это сервисы по поиску закупок как для поставщиков, так и для заказчиков.
- Заказчикам: обоснование НМЦК, автоматическая проверка СНИПов, ГОСТов и других норм, анализ уровня цен на товары;
- Поставщикам: поиск закупок (в том числе малого объема), проверка организаций, проверка СНИПов, ГОСТов, проверка электронных подписей.
Предыстория
СТАР разрабатывался как агрегатор закупок с удобным поиском. Проект должен был помочь компаниям-поставщикам эффективно находить тендеры, в которых заказчик ищет соответствующие товары или услуги, предоставляемые поставщиком. Для этого мы разработали морфологический поиск, с помощью которого пользователи могли искать одновременно до 5 наименований, введя запрос в любой словоформе.
Заказчикам же СТАР предлагал две функции – создание документа «Обоснование начальной (максимальной) цены контракта НМЦК)» и автоматическую проверку СНиПов и ГОСТов в документации заказчика прямо на сайте.
О запуске проекта мы уже писали в кейсе «Создание универсального сервиса для работы с закупками».
Команда
Мы продолжаем развивать проект: за время его развития выделилось несколько векторов разработки – в связи с этим выросла и команда. На старте она была небольшой, но за время совместной работы многократно выросла – сейчас с проектом работает более 20 специалистов под руководством трех тимлидов.
Анализ цен и рынка
СТАР обрабатывает и сопоставляет данные, поэтому одна из его основных задач – анализ опубликованных закупок и товаров.
Для этого доступны два основных сервиса:
- Реестр поставщиков;
- Общедоступный анализ цен.
Эта информация помогает поставщикам и заказчикам понять уровень спроса на интересующие их товары, оценить динамику рынка и цен.
Обоснование НМЦК
При открытии тендера по 44-ФЗ или 223-ФЗ необходим документ по обоснованию НМЦК (начальной минимальной цены контракта). Создать его можно прямо на портале. Для этого нужно ввести наименование и вид товара, работ или услуг. СТАР произведет расчет среднерыночной стоимости, опираясь на имеющиеся данные заключенных контрактов.
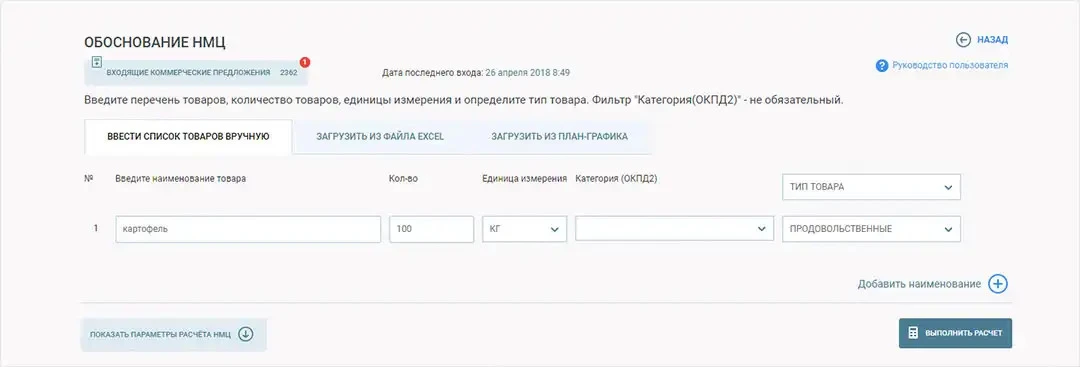
Старый сервис НМЦК
Со временем мы значительно расширили параметры расчетов НМЦК. Теперь пользователь может ввести наименование, количество, единицу измерения товара и его категорию по ОКПД2, а также выбрать, в каких товарах искать цены по контрактам – 44-ФЗ или 223-ФЗ, указывать статус контракта, дату окончания и подписания и регион заказчика. Исключать контракты выбранных организаций из выдачи можно, указав наименование или их ИНН.
Пользователям доступны настройки расчета цен для НМЦК: например, можно выбрать, учитывать ли при расчете индекс потребительских цен и включать ли в него контракты, заключенные ранее 6 месяцев назад.
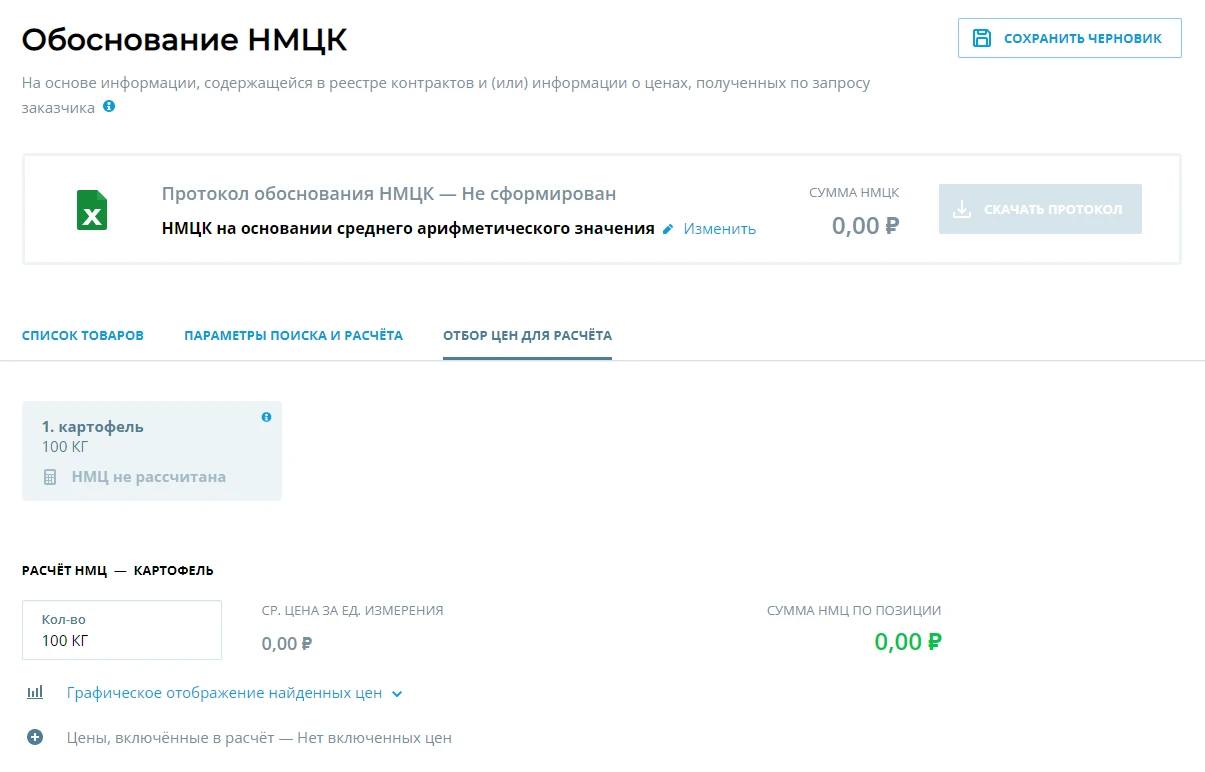
Фильтры
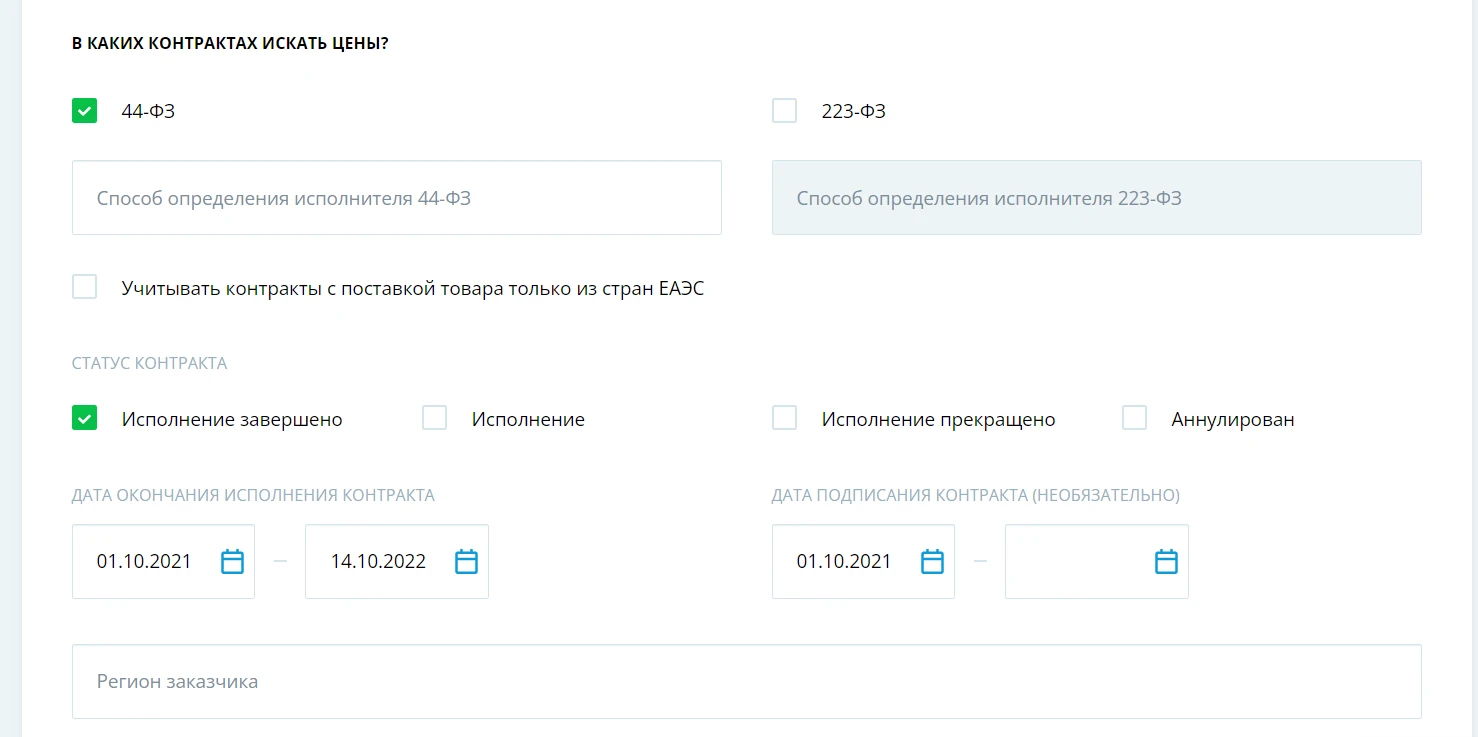
Фильтры
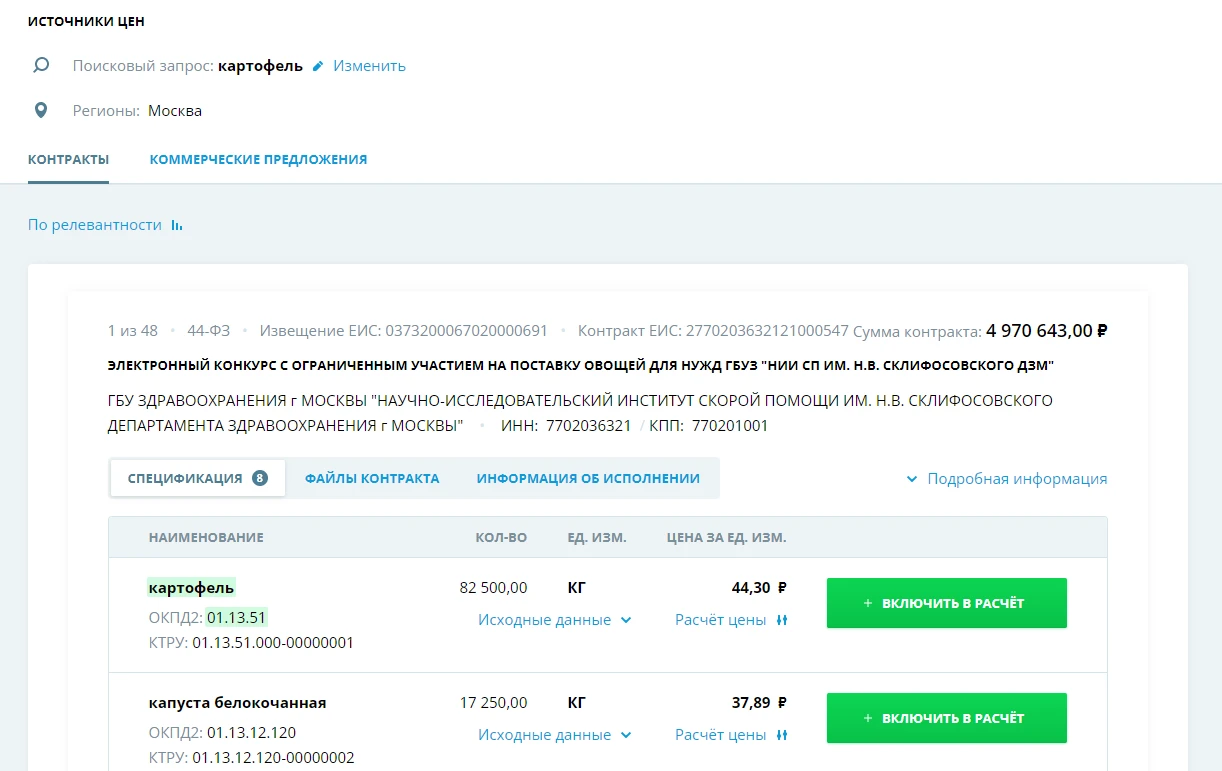
Выдача в обновленном сервисе НМЦК
Как видим, в новой версии сервиса расширился состав фильтров и настройки параметров для расчета. Расширение функционала и оптимизация пользовательского интерфейса позволяют заказчикам эффективно формировать закупочную документацию.
Подбор поставщиков и заказчиков
Это еще один крупный сервис СТАР. Важной задачей для b2b-сегмента является поиск контрагентов. С одной стороны заказчики ищут себе поставщиков для реализации своих контрактов, с другой – поставщики ищут заказчиков для реализации своих товаров и услуг.
СТАР пытается помочь им в решении этой задачи. Для этого он предоставляет сервисы, которые связывают поставщиков и заказчиков:
- Подбор покупателей и заказчиков по заданным параметрам;
- Автоматическое приглашение в закупку, которое позволяет отобрать поставщиков по товару, цене и регионам.
СТАР также решает рутинные задачи клиентов. Например, с его помощью можно автоматически формировать и проверять закупочную документацию. Не нужно тратить время на ручной поиск поставщиков: кроме автоматического сопоставления по товарам, мы создали автоматическую рассылку – поставщики получают подборку с предложениями от заказчиков, основанную на ранее опубликованных предложениях и поисках.
Разработка СТАР на этом не заканчивается. Мы продолжаем создавать новые сервисы для автоматизации других процессов заказчиков и поставщиков, а также сервисы, необходимые по новым требованиям законодательства – например, сервис квотирования закупок, сервис обоснования НМЦК лекарственных средств и т.д.
Обновленная технология поиска похожих фраз
В основе этого сопоставления поставщиков и заказчиков лежит установление связи между товарами и услугами поставщика и заказчика.
Для выполнения такого поиска мы использовали ElasticSearch – с его помощью можно организовать поиск по огромным базам данных. Однако он не совсем подходит для сопоставления коротких наименований товаров.
Дело в том, что такой поиск не учитывает синонимы и контекст, в которых употребляются слова. Так, фразы «красное дерево» и «синяя ручка» имеют в себе слова, обозначающие цвет. Но понимаем мы их по-разному: в первом случае говорится о виде древесины, во втором – о цвете туши внутри ручки. При этом во фразе «красная ручка» мы также подразумеваем красную тушь, а значит семантически эта фраза ближе к «синей ручке».
Наше решение предполагает совмещение функций поискового движка ElasticSearch и подходов NLP (Natural Language Processing – обработка естественного языка), направления искусственного интеллекта и математической лингвистики. Благодаря им, мы можем учитывать значения слов в зависимости от их контекста при поиске.
Одна из задач NLP – поиск парафраз. Парафраза – это выражение, которое описанием передает смысл другого выражение. Известный пример такого описания – «пишущий эти строки» вместо «я» или «автор». Использование такого поиска позволяет анализировать текстовое описание товаров у заказчика и сравнивать его с описанием товара у поставщика и наоборот.
Изначально для поиска парафраз мы использовали нейронную сеть BiLSTM, но позднее перешли к более сложной модели – BERT. Подробнее о том, как мы применяем машинное обучение для полнотекстового поиска можно почитать в статьях руководителя группы разработки проекта СТАР Юрия Басалова: Как построить полнотекстовый поиск с помощью нейронных сетей и Как с помощью BERT организовать поиск похожих текстов.
Преобразование неструктурированных данных
В базе проекта СТАР – структурированные и неструктурированные данные о закупках и предложениях поставщиков. Неструктурированные данные – это приложенные к закупкам документы.
Чтобы повысить точность сопоставления товаров и закупок, мы разработали технологию, которая может учитывать информацию из приложенных документов – текстовых файлов, сканов изображений и счетов фактур.
После извлечения информации из документов мы получаем относительно структурированную информацию о товарах или параметрах контракта – сроках оплаты, наличия аванса и т.д.
Извлечение данных из описания лекарств
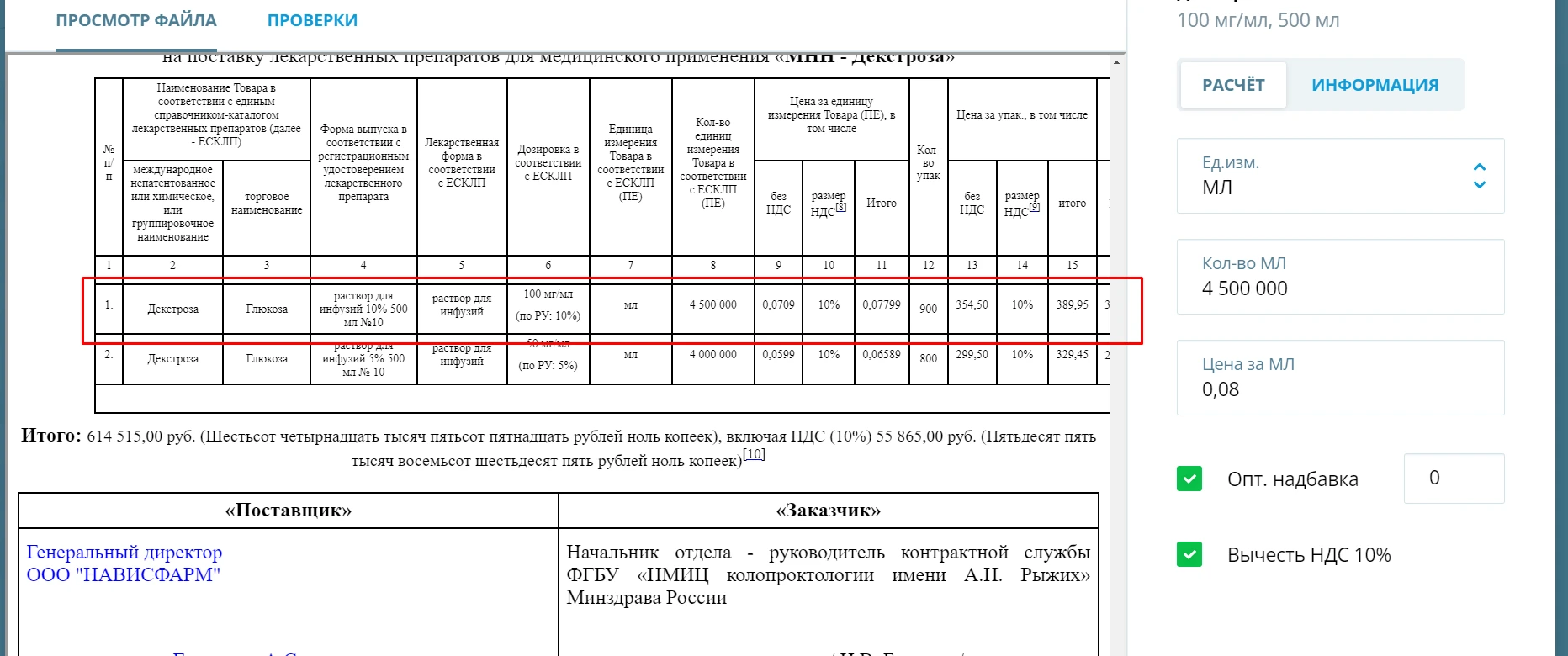
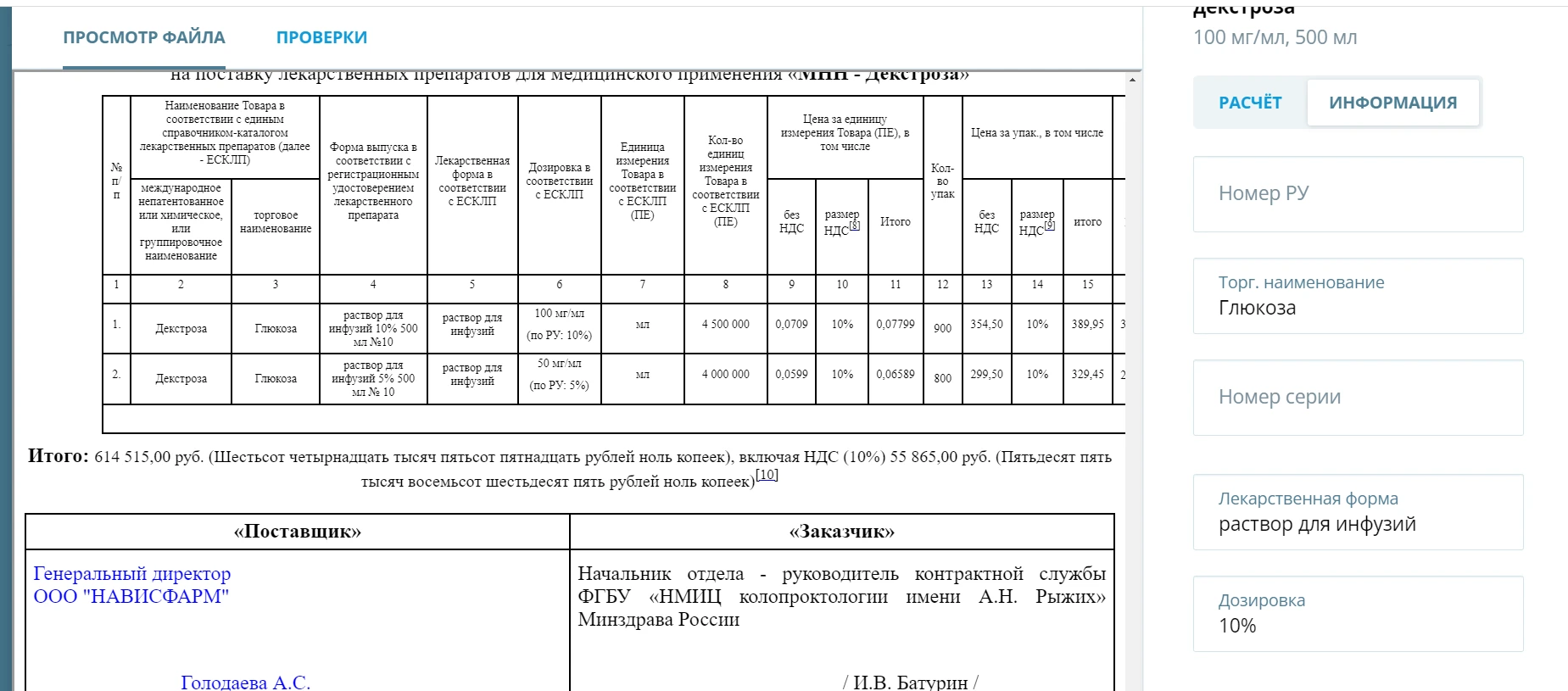
Отдельно отметим технологию извлечения данных из документов к закупкам лекарственных средств. В описании лекарств много параметров – состав, дозировки, форма выпуска и т.д. Важно максимально точно сопоставить закупку и описание. Эту задачу мы также решили с помощью машинного обучения.
Для правильного сопоставления мы извлекаем информацию о лекарственных средств из документации. В закупке и описании товара должны быть указаны МНН, название, форма выпуска и дозировка препарата.
Следующий шаг – определение единицы измерения вещества. Она может быть указана, например, в штуках (для таблеток), в миллиграммах, миллилитрах и т.д. Не во всех закупочных документациях этот параметр прописывают явно, поэтому для его определения мы используем простую нейронную сеть. Из документации извлекаем информацию о дозировке и форме выпуска, а нейронная сеть определяет способы хранения препарата и возможные единицы измерения.
Получив информацию о единицах измерения, мы можем рассчитать цену – например, за количество таблеток или за миллиграммы.
Стек технологий
- Elastic Search
- C#
- .Net Core
- Java
- Python
- MS SQL
- MongoDB
- ClickHouse
- RabbitMQ
- React
- Remix
Архитектура поискового модуля
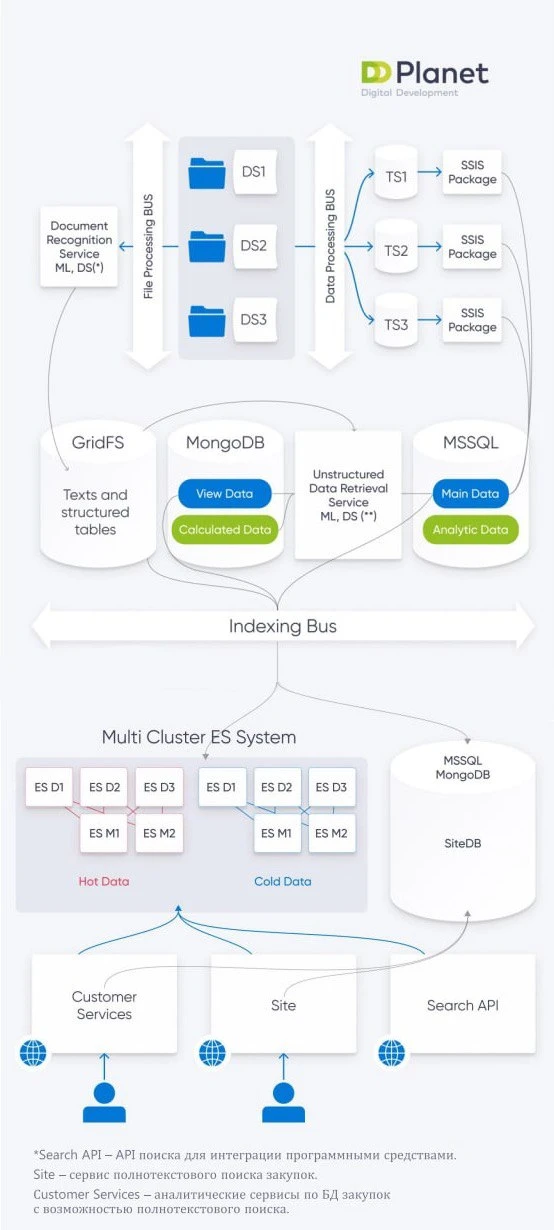
Источники данных
DS1, DS2, DS3 – FTP источники данных (примерно 100000 XML в день)
Извлечение, обработка, систематизация
Document Recognition Service ML, DS(*) – система распознавания отсканированного текста и таблиц (из Word, Excel, PDF, изображений);
File Processing Bus – распределенный сервис многопоточного скачивания и сохранения файлов;
Data Processing Bus – интеграция с источниками закупок;
Данные получаются через FTP-выгрузки и API. Затем с помощью системы парсинга попадают в БД, а затем – собираются в единое хранилище DWH (объемом ~2 Тб) на сервере MSSQL.
GridFS содержит ~10 миллионов извлеченных текстов и таблиц из файлов PDF, а MongoDB – структурированные данные и тексты из таблиц файлов. Для получения конечной информации используется Machine Learning.
Результаты
- Всего на сервисе зарегистрировано 96 тысяч пользователей.
- В системе хранится информация о более 30 млн тендеров от 400 тысяч заказчиков. Она занимает несколько терабайтов памяти и используется для поиска и анализа рынка.
- Сбор данных из более 30 открытых источников: интернет-магазинов; агрегаторов, специфических порталов в сегменте b2b-закупок.
- В базе данных – сотни миллионов товарных позиций от миллионов поставщиков.
- Каждый рабочий день добавляется до 15-20 тысяч новых закупок.
