

- Заказчик
- WeighMyRack — американская прайс-площадка, помогающая любителям скалолазания подобрать экипировку по выгодной цене.
- Задача
- Масштабирование импорта за счёт подключения более 10 дополнительных фидов, рефакторинг кода, обновление CMS, устранение багов из имеющейся функциональности, улучшение производительности и интерфейса
Это непростой проект, а потому в тексте присутствует кое-какие специфические понятия, дать которым определение мы считаем своим долгом.
Ритейлер — сайт или магазин, который продает товары и предоставляет нам потоки данных, или фиды.
Фид — поток данных. В нашем случае это .csv или .txt-файл, содержащий всю необходимую информацию о товаре и обновляющийся раз в день.
Импорт — процесс обновления информации, полученной из фида.
Main-сервер — главный сервер для работы с данными, которые видит пользователь на сайте.
Sync-сервер — вспомогательный сервер для вычислений.
Контрибный модуль — Drupal-модуль, развиваемый сообществом.
О клиенте
Компания ADCI Solutions познакомилась с соосновательницей WeighMyRack в конце 2018 года, а в начале 2019 начали работу. Ей требовалась команда с глубокой экспертизой в Drupal для сложного проекта, и как можно скорее — разработчики из команды поддержки сайта решили закрыть своё агентство. После технического интервью и нескольких переписок клиент выбрал нас. Мы до сих пор продолжаем сотрудничество.
О сайте
Компания WeighMyRack позиционирует себя как прайс-площадку с возможностью для сравнения цен между товарами. В качестве российских аналогов можно было бы привести Яндекс.Маркет и price.ru. Но WeighMyRack специализируется только на товарах для скалолазов, что делает его ближе к нишевым сервисам podarki.ru, mobiguru.ru и kolestorg.ru, подсказывающим цены в магазинах подарков, мобильных устройств и автозапчастей соответственно. WeighMyRack не является магазином сам по себе и зарабатывает на процентах с продаж, совершаемых пользователями, перешедшими с прайс-площадки на сайт производителя скалолазного снаряжения.
Перед нами стояла задача масштабировать импорт за счёт подключения более 10 дополнительных фидов, сделать рефакторинг кода, обновить CMS, устранить баги из имеющейся функциональности, улучшить производительность сайта и интерфейс.
Что получил клиент:
- рост показателей сайта в Google Speed Insights и, как следствие, рост его производительности;
- улучшение клиентского опыта за счёт увеличения числа подключенных магазинов и новых фильтров;
- модули, очищенные от неработающего кастомного кода;
- двукратное ускорение обновления данных о товарах;
- техподдержку.
Теперь о том, как нам дался этот успех.
Добавляем новую функциональность
Ключевая функциональность сайта собрана на страницах с категориями товаров. Здесь пользователь может:
- найти нужный товар, фильтруя его по бренду, цене, цвету, форме, размеру, весу, полученных наградах и скидках;
- сравнить цену на товары в разных магазинах;
- оставить отзыв;
- добавить товар в свой список;
- добавить товар в вишлист;
- продолжить покупку, перейдя с сайта WeighMyRack в любой онлайн-магазин.
Мы улучшили UX этих страниц, в частности с помощью Drupal-модуля Facet API сделали несколько новых фильтров, использующих информацию из фидов (страна магазина, который продает товар, скидки и т. п.).
Чистим сайт от неработающего кода
Копаясь у сайта во внутренностях, мы нашли контрибные модули и темы, код которых не соответствовал коду тех же модулей и тем, хранящихся в репозитории Drupal. Так делают, чтобы заставить модуль решать изначально не предполагавшиеся для него задачи. Но формально такие изменения считаются багами, а усугубляло ситуацию то, что модули не получали обновлений безопасности 2-3 года. В метафорическом смысле это делало из проекта в минное поле.
Что это значит на практике? Во-первых, стоило попытаться обновить доработанный модуль до какой-нибудь версии, и всё могло сломаться; во-вторых, баг может воспроизводиться на одной единственной странице раз в месяц; и в-третьих, никогда не известно, насколько большую роль играли эти доработки в жизни сайта — может, выводили текст на странице покрасивее, а может, изменяли работу с базой данных.
Порой бывает сложно сказать, насколько сильно влияют изменения в коде на общую работу сайта. Хорошо, если код написан чисто, с комментариями и без багов. А что, если комментариев нет? А если связи с разработчиком не имеется? Поэтому прежде чем начинать работать, нужно было понять глубину изменений в модулях.
В итоге мы почистили модули от неправильного кода ровно настолько, чтобы можно было обновить сайт и не разрабатывать его с нуля.
Сохраняем данные максимально свежими
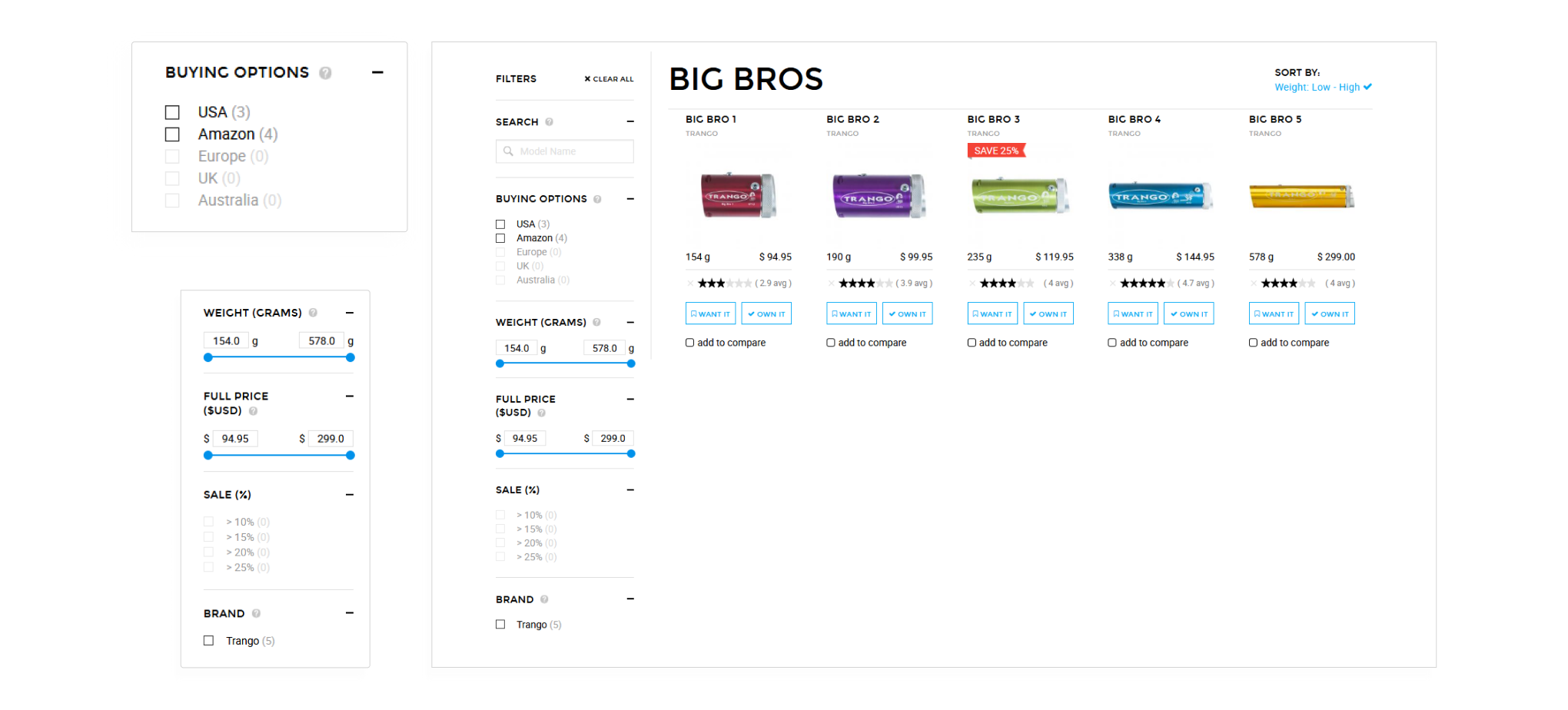
Работу сайта с данными обеспечивали два сервера: main и sync. Первый занимался обработкой пользовательских запросов, второй — импортом данных. Они связаны между собой с помощью Jenkins — системы, которая позволяет автоматизировать процессы разработки и деплоя.
Почему двумя задачами не мог заниматься один сервер? Залог успеха любого сайта — быстрая загрузка. Это любят все. Если бы в нашем случае импорты происходили на main-сервере, пользователь во время загрузки страницы успевал бы выпить чашку кофе. Поэтому пока один сервер занят длительной монотонной вычислительной работой, другой работает с пользователями.
Контент-менеджер WeighMyRack создаёт на main-сервере страницы с товарами, следит, чтобы информация была актуальной, и прописывает уникальные идентификаторы товара, благодаря которым можно соотнести строчки из фидов со страницами товаров на сайте.
А пока контент-менеджер что-то меняет на main-сервере, на sync-сервере может происходить импорт. И то, и другое меняет базу данных, и нам надо было сохранить все. А если какой-то из серверов упадёт, важно было иметь максимально свежие данные.
У нас уже был настроен модуль backup_migrate, делающий бэкапы на сервере раз в день по таймеру, а также имелись еженедельные бэкапы на хостинге Digital Ocean. Но этого было мало, и, чтобы заставить два сервера работать в унисон с базой данных, мы написали скрипт, который делает ежедневные бэкапы данных перед началом очередного импорта и записывает их в бэкап-хранилище на удалённом сервере с отладочным сайтом.
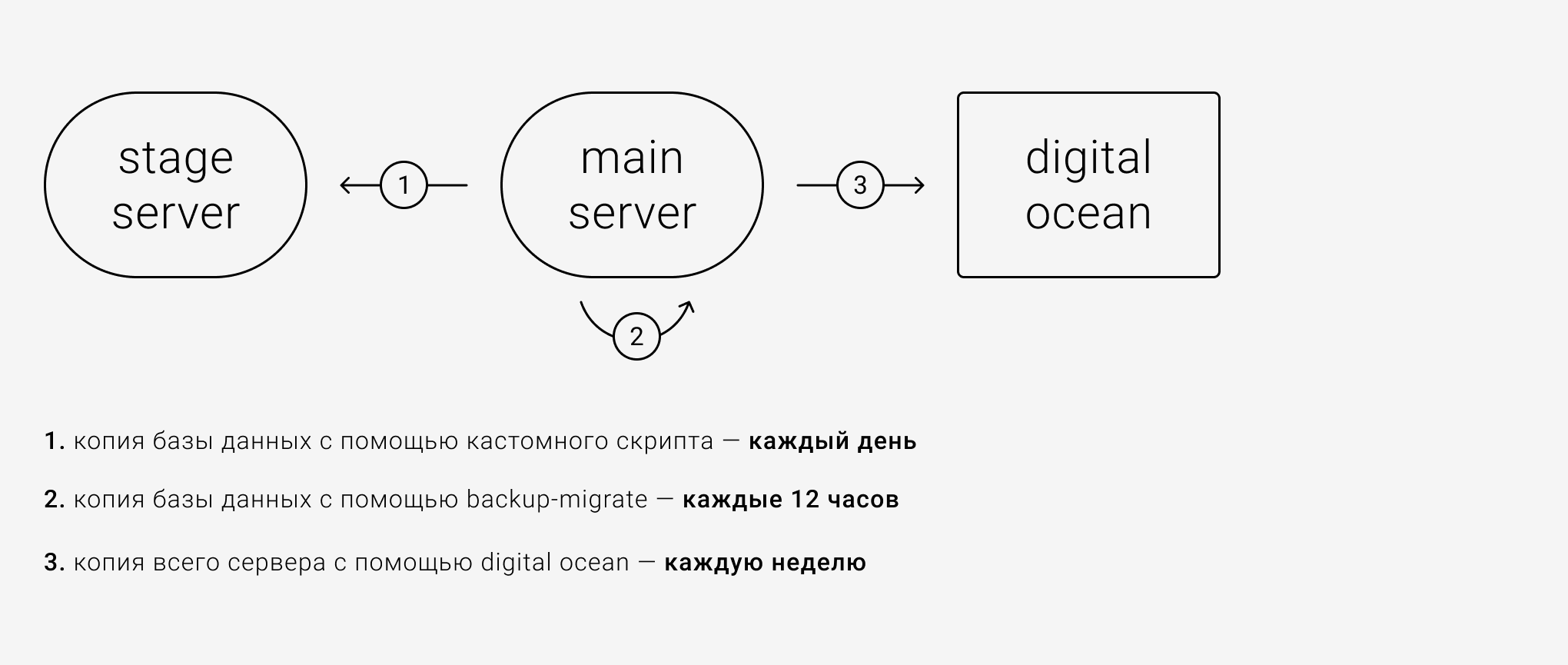
Это дало нам уверенность, что обновленная информация появится на рабочем сайте. И если основной сайт упадет, у нас все равно будет бэкап менее, чем 12-часовой давности.
Ускоряем обновление данных в два раза
Когда ритейлеров было два, система импорта работала примерно так. Скрипт для каждого фида вытаскивал из них информацию, на основе которой обновлялась страница товара на сайте. Скрипты запускались последовательно, и как только оба импорта заканчивались, мы объединяли обновлённую информацию о товарах на sync-сервере и возможные изменения на main-сервере.
В среднем эти два канала обновлялись 3-5 часов. Но клиенту нужно было развивать бизнес и добавлять ритейлеров. Когда мы это сделали, закономерно увеличилось время полного импортирования. В какой-то момент оно выросло до 24 часов, с чем нельзя было мириться.
Как снизить время? Обрабатывать фиды не последовательно, а параллельно. В этом случае мы имеем дело с многопоточностью, когда несколько запросов пытаются одновременно получить доступ к одной и той же информации.
Для описания многопоточности напрашивается аналогия с библиотекой. Посетитель просит книжку, но оказывается, что она есть в одном экземпляре, который кто-то забрал. Придётся ждать, пока книгу вернут. В этой аналогии книга — это страница товара, в которую пишутся данные, а посетители библиотеки — потоки, которые хотят писать данные.
Но Drupal не ждёт, когда вернут книгу, а идёт домой к человеку, который ее читает, и не просто садится читать рядом, но и дописывает что-то в нее. В этом и был конфликт: невозможно предугадать, чьи изменения сохранятся. А нам нужно было сохранить каждое.
Когда мы тестировали обновление для 1000 продуктов, обновлялись только 500-600. В поисках решения мы встроили lock mechanism — «замок», позволяющий контролировать данные и не дающий вмешаться другим процессам, пока данные зависят от текущего.
Рассмотрим абстрактный пример работы lock mechanism. P1 и P2 — это процессы, вносящие изменения в файл.
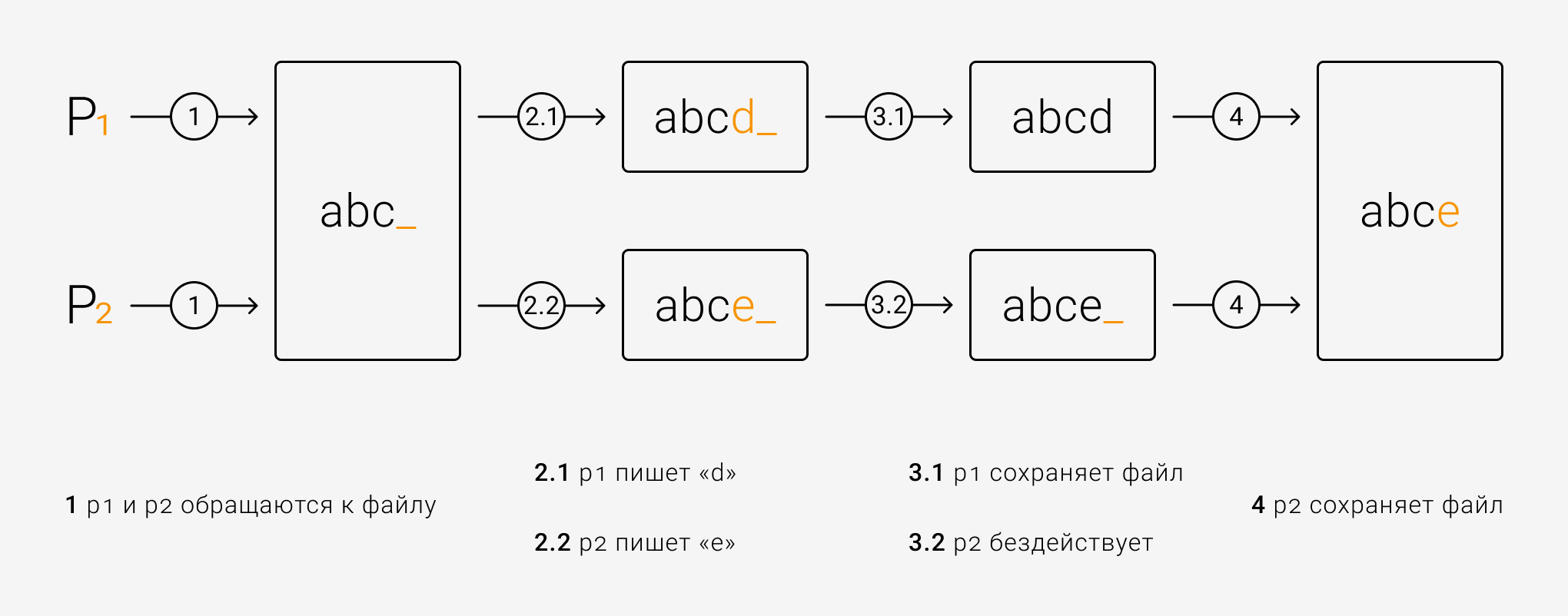
Работа без lock mechanism. На этапе 3.2 P2 не знает об изменениях со стороны P1, поэтому во время сохранения переписывает изменения, внесённые P1. Проще говоря. без lock mechanism невозможно предугадать, чьи изменения сохранятся.
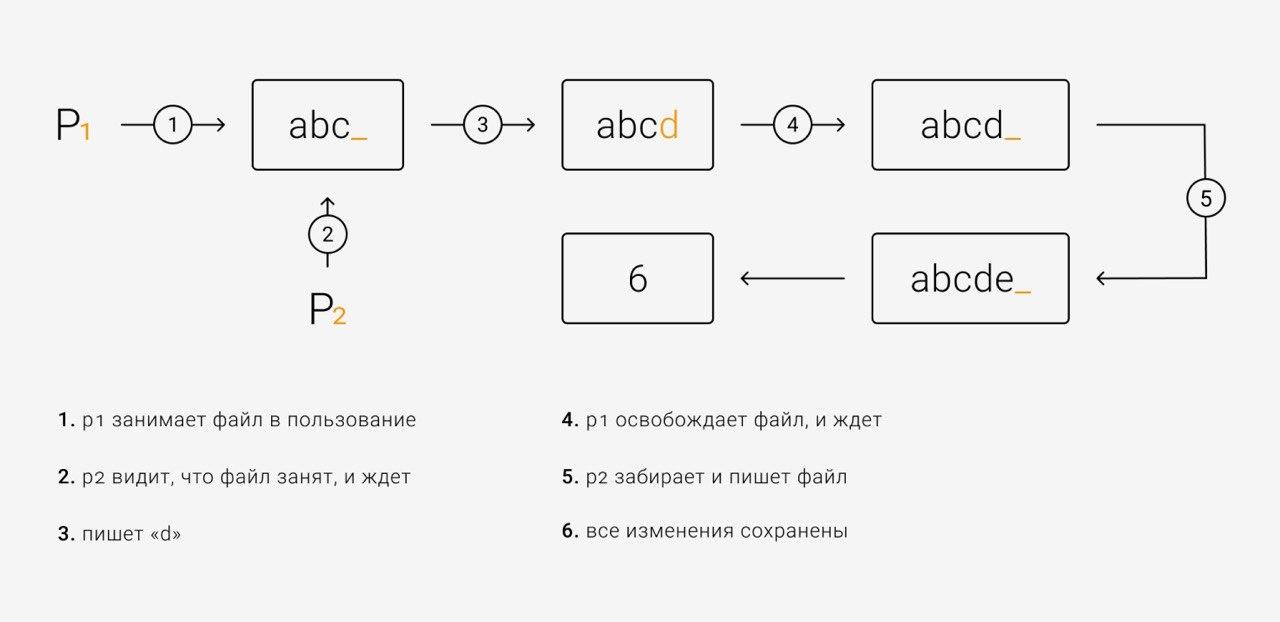
Работа с lock mechanism. Пока один процесс пишет изменения, второй ждёт свой очереди.
Защищаем сайт от DDoS-атак
Суть DDoS-атак — в огромном количестве запросов, под натиском которых база данных MySQL не справляется со своей работой, и не рассчитанный на такую нагрузку сайт падает. За время работы на проекте атаки случились 3-4 раза. Приятного в этом мало, поэтому мы установили систему для мониторинга и возобновления процессов Monit. Благодаря ей тот или иной процесс или сервис перезапускался спустя 3 минуты после того, как MySQL, Apache или httpd переставали отвечать, и сайт продолжал работать нормально — удобно, если DDoS-атака производится ночью.
Ускоряем загрузку сайта
До нашего участия PageSpeed Insights показывал 1-2 из 100 на подавляющем большинстве страниц. Сейчас сайт откликается и грузится в разы быстрее прежнего — помогли оптимизация сервера, подключение агрегации css/js и использование технологии Lazy Load для особо тяжелых страниц.
Перспективы
Мы сохраняем отношения и разрабатываем новую функциональность. Готова к релизу страница, где перечислена только продукция последнего года. Также в процессе — система глобального поиска по сайту, который понимает, что искал пользователь, и редиректит их на страницы брендов, типов снаряжения и т. п.
Остались вопросы? Задайте их в письме: hello@adcillc.com
Этот проект не похож на ваш? Посмотрите, что ещё мы сделали:
- разработали CRM для международного консалтингового агентства, которая предусматривает медленный интернет и возможные обрывы соединения;
- подняли конверсию на сайте установщика солнечных панелей за счёт упрощения структуры сайта и оживления интерфейса;
- сделали редизайн сайта изготовителя рольставен;
- быстро перенесли сайт с одной версии CMS на другую, не затронув дизайн, с помощью принципа мультисайтинга;
- привели агентству инфлюенс-маркетинга первых лидов с помощью сайта;
- увеличили число клиентов детской клиники, обновив версию CMS на сайте и серьёзно переработав дизайн. сохранить
