

Локализация и рывок вперед: новый подход к хранению данных в Hoff на облачной платформе Yandex Cloud
- Заказчик
- Сеть гипермаркетов Hoff — одна из крупнейших российских и динамично развивающихся мебельных сетей. Это единственная российская сеть мебели и аксессуаров для дома, работающая в формате гипермаркета.
Задача
Hoff обратились к нам в октябре 2021 года за корректировкой разметки web-аналитики. После нескольких консультаций стало ясно, что истинный запрос клиента гораздо шире — в области работы с большими данными.
В компании существует два хранилища, на основе которых работает глобальная аналитическая система Hoff:
Внутреннее, в котором лежат ключевые данные ритейлера (продажи по товарам, регионам и др).
Облачное DWH (data warehouse), которое использовалось для работы продуктовых и маркетинговых аналитиков.
Для повышения эффективности и качества работы Hoff собирает большое количество информации: звонки, визиты, обращения, оплаты, действия клиентов на сайте и многое другое. За 5 лет в хранилище накопился внушительный пул данных об онлайн-заказах и поведении пользователей, а также легаси-код, который замедлял выполнение новых аналитических задач.
Структура хранилища DWH на базе Google Cloud Platform влекла за собой недочеты, которые ставили под вопрос качество собираемой информации. Сырые данные из более чем 10 источников стекались в BigQuery, использовались для 155 дашбордов и занимали 1938 расчетных полей в 42 отчетах. Иногда данные могли противоречить друг другу, что усложняло принятие решений для бизнеса.
Эта система позволяла закрывать текущие задачи компании, но для достижения новых амбициозных целей, которые ставил перед собой Hoff, требовался переход на качественно новый уровень работы с данными.
Целью проекта стал рефакторинг облачного хранилища. Главной задачей Aero было привести онлайн-данные в порядок: создать единые принципы хранения, разработать масштабируемую архитектуру, выстроить правильную систему алертинга для регулярного контроля качества. В общем, сделать облачное хранилище понятным и структурированным источником информации для Hoff.
Решение
Дискавери-фаза
Начали с анализа старой структуры: требовалось понять и описать картину as is, поэтому мы провели реверсивный инжиниринг. Начиная с конца, то есть от дашбордов, по цепочке «шли» к сырым данным в источниках, попутно выявляя все последовательности и правила преобразования.
Это был один из самых сложных этапов, потому что потоки данных в облаке на старте проекта выглядели следующим образом:

Факты, которые мы обнаружили:
Из 93 ТБ данных в BigQuery почти треть — ненужные или устаревшие.
Объем еженедельных запросов к хранилищу из PowerBI составляет 29 ТБ.
Обработка запросов данных стоит компании порядка 3000$ в месяц.
В общем, всё работало долго, дорого и сложно. Стало ясно, что нужно не только оптимизировать облачное хранилище, но и выстроить универсальный регламентированный процесс сбора, очистки и обработки данных для масштабирования аналитики в Hoff.
Спасение данных и переезд в Yandex Cloud
Сразу после аудита мы предложили перейти из BigQuery на open-source решения в Yandex Cloud, так как на текущем этапе развития платить за каждое обращение к данным было нерационально. Это казалось рискованным предложением на фоне привычных сервисов Google, но в феврале картина мира резко изменилась — риск отключения стал стимулом к локализации хранилища. Hoff доверился нашей экспертизе, и мы незамедлительно инициировали бэкап данных, параллельно разрабатывая архитектуру совместно с командой Yandex Cloud.
Как без паники выгрузить 93 ТБ данных ASAP, пока Google рассылает «письма счастья»? В этом помог аудит. С коллегами из Hoff оперативно решили, какие данные можем не забирать, прописали скрипты для разных сценариев выгрузки в Yandex Object Storage и подняли 3 виртуальные машины для синхронизации хранилища. Команда Yandex Cloud экстренно подключилась к процессу, рассказала об архитектурных особенностях облачной платформы и помогла подсчитать бюджет.
Нам понравились их управляемые сервисы для СУБД ClickHouse и Greenplum: их использование позволяет снять с себя обслуживание инфраструктуры, обеспечение отказоустойчивости и проверку исправности в процессе раскатки обновлений. В общем, Yandex Cloud следит, чтобы железо и базы данных работали бесперебойно, что позволяет сфокусироваться на развитии проекта.
Благодаря проактивности всех участников процесса и помощи аналитиков из Hoff, уже спустя месяц у нас был доступ к историческим данным на случай отключения инфраструктуры Google.
Чем хорош open-source
Clickhouse и Greenplum — это бесплатные сервисы с открытым исходным кодом, над которыми работает большое количество разработчиков. Из-за этого они, как правило, содержат меньше дефектов, быстрее обновляются и в целом обеспечивают гибкий рабочий процесс. При желании клиента, текущую архитектуру Hoff можно быстро перенести из облака на локальные сервера без потери данных, в то время как BigQuery заставляет буквально с нуля пересобирать все хранилище.
В то же время open-source — это про стабильность. Блокировка сервисов поставила под сомнение существование экосистемы данных множества компаний, а открытые решения снимают подобные риски.
Разработка архитектуры
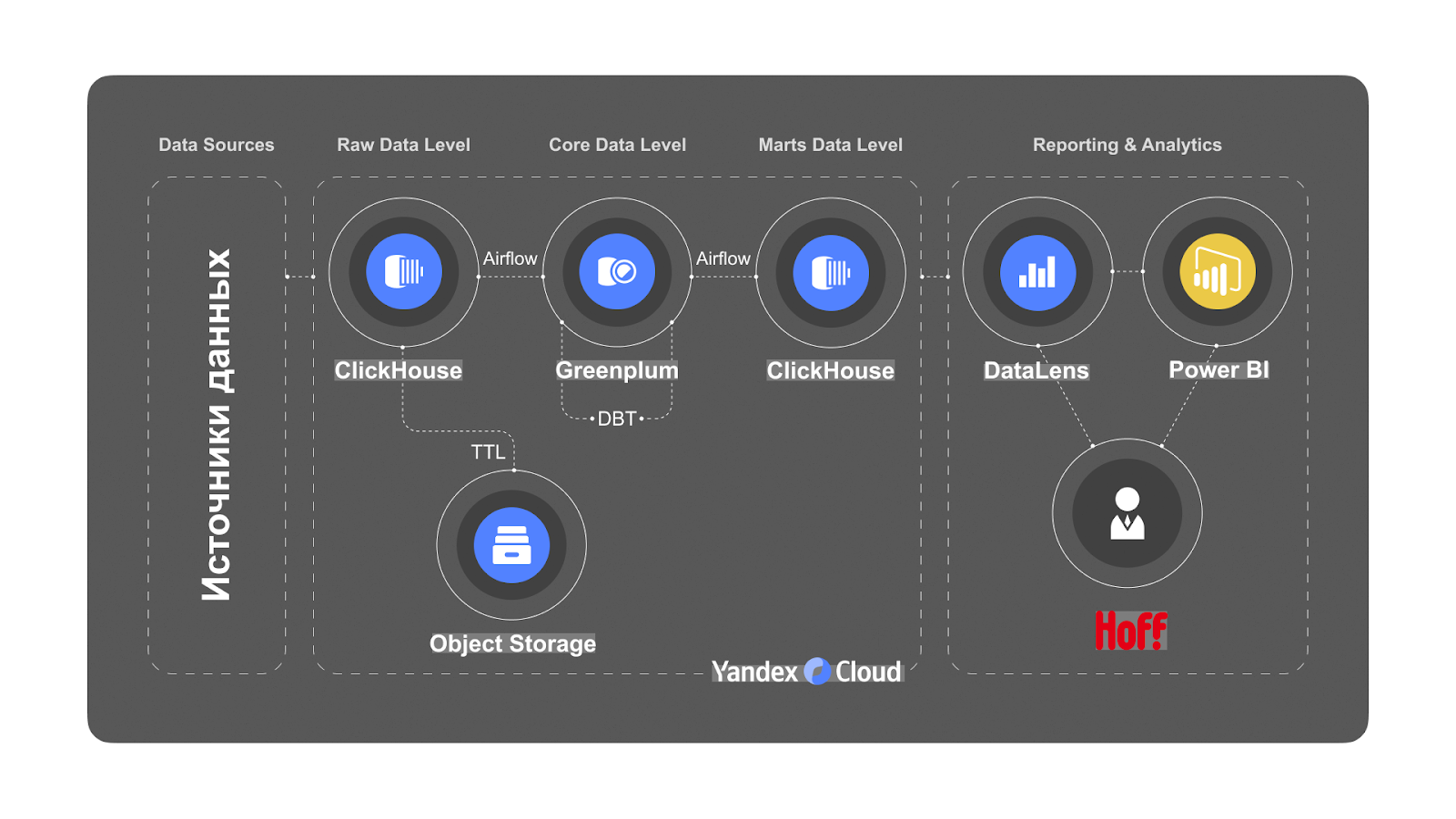
Мы решили послойно развернуть хранилище в разных системах управления.
Clickhouse хорошо работает с сырыми данными: за счет высокого сжатия хранилище занимает меньше места, но при этом даже единичные ad hoc запросы выполняются оперативно. Для ядра DWH выбрали Greenplum. Благодаря распределенной обработке, в нем можно быстро изменять, фильтровать и связывать данные. В BigQuery аналитики Hoff работали только с raw data level, то есть с сырыми данными, которые мы перенесли в Clickhouse вместе с коннекторами. Предобработанные данные упорядочили в Greenplum в виде Data Vault 2.0.
Это гибридная модель, суть которой — дробление массива данных на логические сегменты. В таком формате удобнее работать с хранилищем: все сотрудники от менеджеров до аналитиков могут компилировать информацию в зависимости от своих потребностей.
В Data Vault переносятся только обработанные с помощью фреймворка DBT данные. Такой подход позволяет доверять информации в хранилище на 100%, не переживая об актуальности и достоверности. С помощью пайплайнов в Airflow мы настроили автоматическое обновление по заданному расписанию.
Так, благодаря четко выстроенным процессам и описанным регламентам, сотрудники Hoff могут поддерживать эту систему самостоятельно.
Алертинг
Надежность хранилища определяется качеством системы оповещений, то есть алертингом. Когда пользователь обращается к данным, он должен понимать их текущее состояние: корректность выгрузки, точность расчетов, последнюю дату обновления. Именно в нашей зоне ответственности сказать бизнесу, если что-то идет не так, предупредить возможные ошибки и принятие неверных решений.
Для новой архитектуры мы с нуля создали полноценную систему оповещений. Теперь при обнаружении ошибки уведомления будут появляться на всех этапах работы с ними — от загрузки сырых данных до дашбордов. При просмотре любого отчета сотрудники могут оценить его актуальность по трехцветной системе маркировки.

Витрины данных
Еще один важный этап работы — создание аналитических витрин или data mart. Это части хранилища в виде агрегированных таблиц, которые содержат данные по разным направлениям деятельности компании. Как правило, это ключевые метрики, которые можно комбинировать различными способами для дальнейшего анализа.
На основе витрин данных строится визуализация: один data mart может быть источником для 600 дашбордов. Ранее они делались из сырых данных, которые перед формированием отчета обрабатывал тот или иной отдел на основе своей экспертизы, а теперь будут создаваться из предобработанной по единому стандарту информации.
Результаты
За год удалось с нуля пересобрать хранилище на облачной платформе и оптимизировать все данные: из 93 ТБ в ядро уложили 51 ТБ регулярно используемой информации. Сейчас ежедневный прирост сырых данных — около 15 ГБ, а в Data Vault — 3 ГБ единообразно обработанных.
За счет алгоритмов и разделения хранилища на слои, аналитики обращаются только к необходимому, подготовленному для работы объему информации. У специалистов стало уходить меньше времени на рутинные отчеты, что открыло возможности для новых проектов по развитию компании.
Преимущества нового хранилища
- Скорость
Промежуточный слой в виде Data Vault значительно ускорил работу сотрудников. В разных компаниях подготовка аналитического отчета может занимать от нескольких дней до недели, в Hoff этот процесс сократился до 20 минут.
Мы с клиентом выработали «гигиенический минимум» — данные в облачном хранилище хранятся так, как удобно бизнесу, а не источникам.
- Масштабируемость
Текущая архитектура спроектирована под нужды Hoff: ее можно наслаивать, модифицировать и расширять в зависимости от запроса. При регулярно растущем объеме данных DWH можно трансформировать в Data Lake без потери качества структуры.
- Достоверность
В облаке появилась единая методология очистки и подготовки данных — теперь вероятность разночтений сведена к минимуму. При появлении нового источника достаточно прописать новый алгоритм, после чего сырые данные будут автоматически приводиться в стандартный вид и попадать в Data Valut.
Детализированная система алертинга построена таким образом, что может оповещать аналитиков о сбоях даже в мессенджерах. Это позволяет оперативно устранять неточности в данных — скорость реагирования на ошибки увеличилась в 3 раза.
- Экономическая целесообразность
Сопутствующей выгодой при реализации проекта стала оптимизация бюджета клиента. Хранилище в BigQuery предусматривало оплату за каждое обращение к данным: помимо того, что при увеличении задач это обходилось компании дороже, всегда был риск потерять сотни тысяч рублей из-за одного ошибочного запроса.
Переезд в Yandex Cloud сделал затраты более предсказуемыми и гибкими. Бюджет при переходе в новое облако не изменился, а количество задач и объем разметки для продуктовой аналитики регулярно растет. Все обработки данных внутри хранилища стали фактически бесплатными — теперь нет никаких платежей, зависящих от количества запросов.
- Технологии
Используемый в проекте технологический стек помогает развивать внутреннюю команду дата-инженеров и усиливает привлекательность компании для соискателей.
